

Artificially intelligent: Salsa Sound on harnessing the power of the data in our audio sensors

Salsa Sound’s co-founders, Ben Shirley [foreground] and Rob Oldfield hard at work
We rely on sensors so much these days, whether that be for temperature, speed, distance, heartrate and more, but often-times we fail to recognise the high volume of contextual data that is available through microphones.
Historically we have viewed microphones only as sound capture devices, but they are far more than that; they are data gatherers and what’s more, they are cheap and we already have several tens of them deployed for every broadcast.
One of the challenges up until now however has been harnessing, extracting and processing the data that comes in audio form to these sensors so we can make use of this valuable data source.
Wealth of information
Thankfully, with advances in artificial intelligence (AI) and machine learning we are now able to extract a wealth of information from these sensors. This information can be used in a variety of different parts of the sport broadcast workflow, improving production efficiency, quality of content, enabling new workflows and fundamentally improving audience experience.
Areas where we have already seen AI for audio benefiting the broadcast industry and areas where we anticipate further development include the following:
- Automated/assistive audio mixing
- Automatic detection of errors/problems in the audio stream
- Auto classification of microphone inputs
- Suggested audio processors to be applied to specific microphones
- Generation of match metadata based on crowd analytics of available microphones
- Real time match metadata extraction – heat maps/play patterns, key event tagging eg ref’s whistle, corners, free kicks
- Additional tracking data source to verify/augment other sources
- Auto-highlight generation
- Graphic triggering
- Speech-to-text on eg, commentary feed for auto-subtitling and content metadata
- Automatic language detection
- Content archives – computing similarities/differences between sources, auto tagging/mining
All this can make it seem like AI is the panacea for all our problems and all you need to do is just throw the AI black box at any problem and it will magically get solved. Sadly, this is not quite the case, and a lot of development goes into successfully implementing and optimising these algorithms. It’s very easy to do AI wrong, but when it is done right it is an extremely powerful tool.
Right tools for the job
It’s also very important to make sure that we are using the right tools for the right job. Some tasks don’t even need AI at all (even if our marketing departments would like to think we were using it!). For the tasks where AI is appropriate, there are many different types of AI to choose from and choosing the correct one will dictate whether the application is successful or not.
 In audio, the most common type of AI is machine learning and in particular the application of deep neural networks (it is this technology for example that Salsa Sound’s automixing solutions utilise). The basic premise of machine learning is to teach a computer to make decisions for you. The exact approaches vary but basically it’s about getting a computer to recognise and categorise data based on previous observations, in much the same way as us humans figure out the world around us (through experience).
In audio, the most common type of AI is machine learning and in particular the application of deep neural networks (it is this technology for example that Salsa Sound’s automixing solutions utilise). The basic premise of machine learning is to teach a computer to make decisions for you. The exact approaches vary but basically it’s about getting a computer to recognise and categorise data based on previous observations, in much the same way as us humans figure out the world around us (through experience).
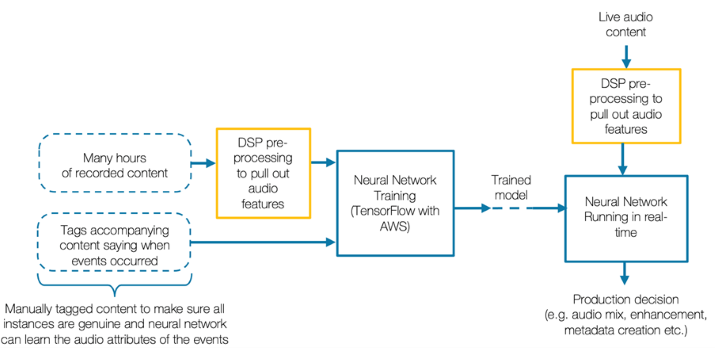
So, what this looks like in a practical scenario is first of all figuring out what exactly you want the machine to recognise (what events are we listening for). The second step is to figure out what stats and data representation you want your computer to use to recognise those events (how are they best described. For example, it is not typical to train a computer just on audio data but rather to put the audio through a pre-processor/feature extraction stage first, for example when we run speech recognition at Salsa Sound, we typically use spectrograms that have been specifically tuned and optimised for perceptually significant bands as this has been proven the most effective method.
Once the best possible data descriptors are found we then need to give the machine loads of examples of the type of sound we are looking for, along with tags (points at which that sound occurred). This is the data that the machine will learn from. It’s like showing a child lots of pictures of penguins and each time telling them, “That’s a penguin”; you do that enough times they will learn to recognise a penguin without needing to be told any more.
A neural network will process all of these training samples and will find a model (complicated stats) that best describes them so that when the new data is input and the same pre-processing algorithms are computed, the machine will be able to classify the audio as being an event of that type (or not). This is the main difference between a traditional software algorithm where you define the input, and the algorithm that gets to the desired output, whereas machine learning you just define the input and the outputs and let the machine figure out the best way of getting from A to B.
Performing better
Perhaps the biggest challenge in this workflow is the manual tagging of the data, as neural networks typically perform better when they are given more data examples and larger data sets. Accurately tagging data is difficult and extremely time-consuming and requires contextually accurate data if it is to be effective.
Once we have our tagged dataset and have put this through a neural network trainer, we will receive as an output a neural network model which can then be let out into the wild running on unseen audio in real time to facilitate all of the exciting opportunities mentioned above.
So, AI isn’t the mystical panacea to all our ills; it requires careful planning, implementation and optimisation, but if used correctly it can improve production efficiency (doing more for less), increase quality of content, enable new workflows and fundamentally improve audience experience.